
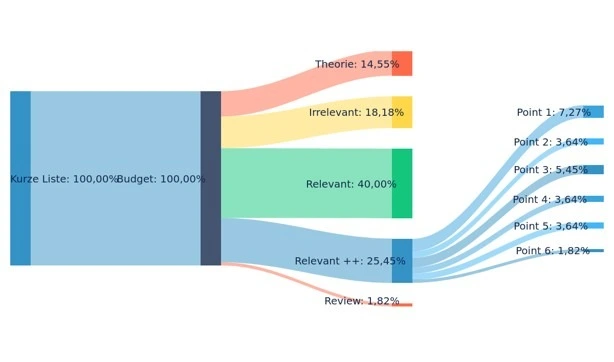
- Anhand von acht Schlüsselbegriffen wurde in Datenbanken (ACM, CVP) recherchiert und dabei 119 Artikel untersucht, von denen 55 ausgewählt wurden.
- Um die 55 interessantesten Artikel zu ermitteln, wurden deren Zusammenfassungen analysiert.
- Alle Artikel wurden anhand der zuvor genannten Schlüsselbegriffe überprüft.
- 14 Relevante ++ Paper
- 1 Review Paper (Direction Net)
End-To-End Wide Baseline Drohnenlokalisierung durch Kamerapose
Motivation
GNSS and AI Based INS System
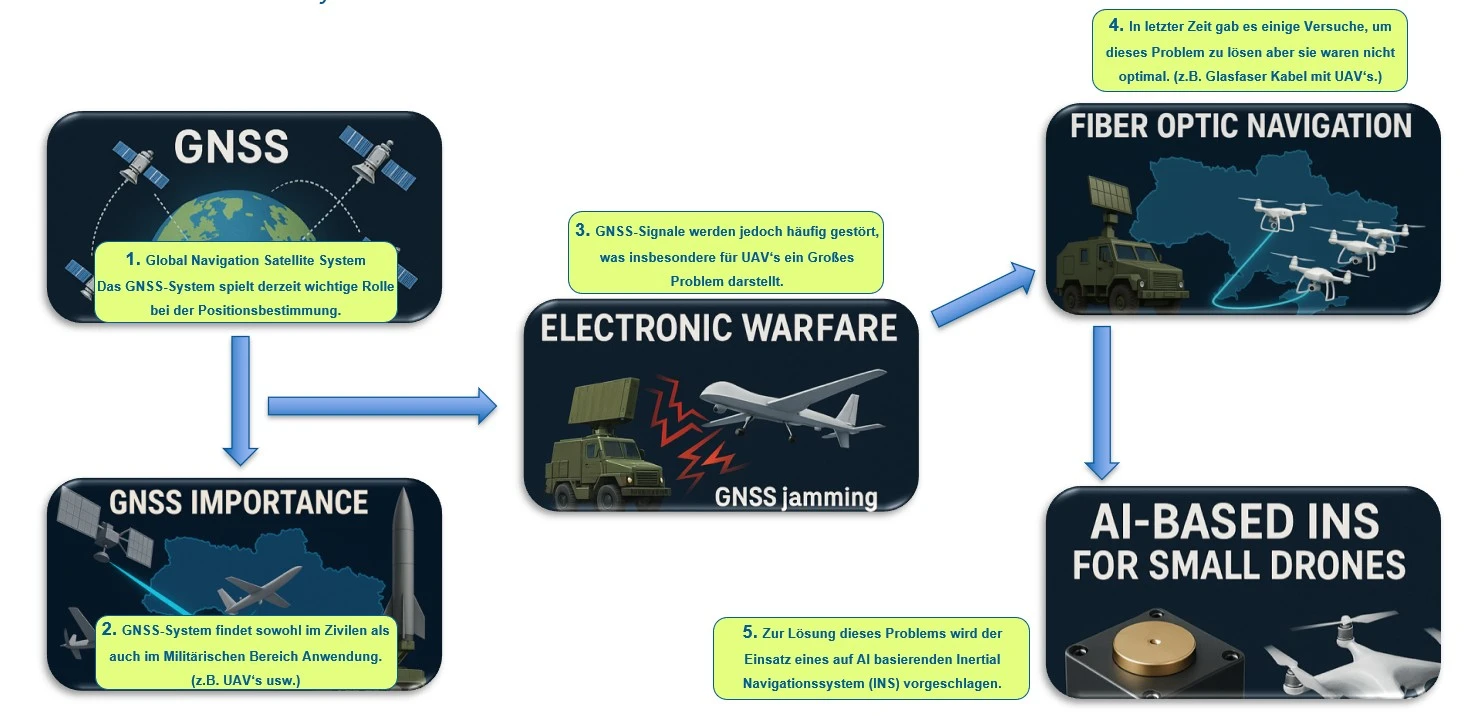
Real World Examples
Literatur Optimierung
Research Input
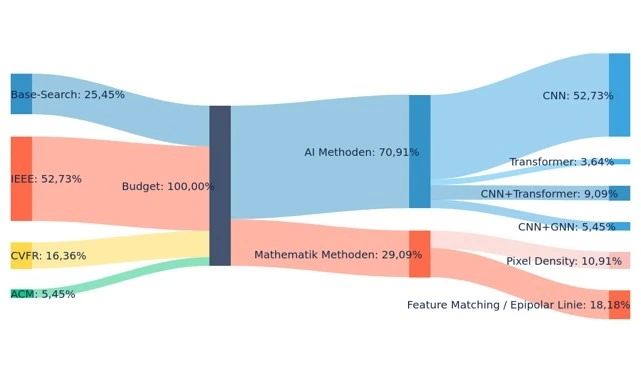
Verteilung der verwendeten Methoden
KI-Methoden (AI-Methods):
- CNN
- CNN + Transformer
- CNN + GNN
- CNN + Transformer + GNN
- Transformer
- Transformer + GNN
Mathematische Methoden (Mathematik Methoden):
- Pixel
- VIO
- ORB-SLAM
In der Grafik bestehen insgesamt 70,91 % der Methoden aus KI-Methoden, während die verbleibenden 29,09 % mathematischen Methoden zugeordnet sind. Innerhalb der KI-Methoden ist CNN mit 52,73 % die am häufigsten verwendete Methode, gefolgt von CNN + Transformer (9,09 %), CNN + GNN (5,45 %) und Transformer (3,64 %).
Bei den mathematischen Methoden ist Feature Matching / Epipolarlinie mit 18,18 % die bevorzugte Methode, während die Methode der Pixel-Dichte zu 10,91 % verwendet wurde.
Betrachtet man die Quellen der Daten, stammen 52,73 % der verwendeten Methoden aus IEEE, 25,45 % aus Base-Search, 16,36 % aus CVFR und 5,45 % aus ACM.
Diese Informationen verdeutlichen, wie verschiedene Forschungsplattformen und Methoden in der Forschung verteilt sind.
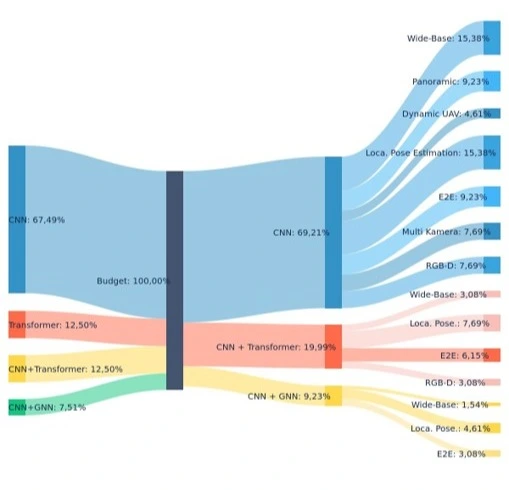
Verteilung nach Anwendungsbereichen
- Wide Base
- Panoramic
- Dynamic / UAV
- Loca. Pose Estimation
- E2E
- Multi Kamera
- RGB-D
Von den Methoden der künstlichen Intelligenz wurde CNN am häufigsten verwendet (67,49 %). Die bevorzugten Anwendungsbereiche für CNN sind insbesondere Localization / Pose Estimation (15,38 %), Wide Base (15,38 %) und Panoramic (9,23 %).
Die Methoden Transformer und CNN + Transformer wurden zu gleichen Anteilen eingesetzt (jeweils 12,50 %). Studien, in denen diese Methoden verwendet wurden, konzentrieren sich vor allem auf den End-to-End (E2E)-Bereich.
Die Methode CNN + GNN wurde zu 7,51 % verwendet und fand vor allem in den Bereichen Localization / Pose Estimation (4,61 %) sowie End-to-End (3,08 %) Anwendung.
Diese Verteilung zeigt deutlich, in welchen spezifischen Bereichen unterschiedliche KI-Techniken effektiv eingesetzt werden.
Use Case
Classic Inertial Navigation System
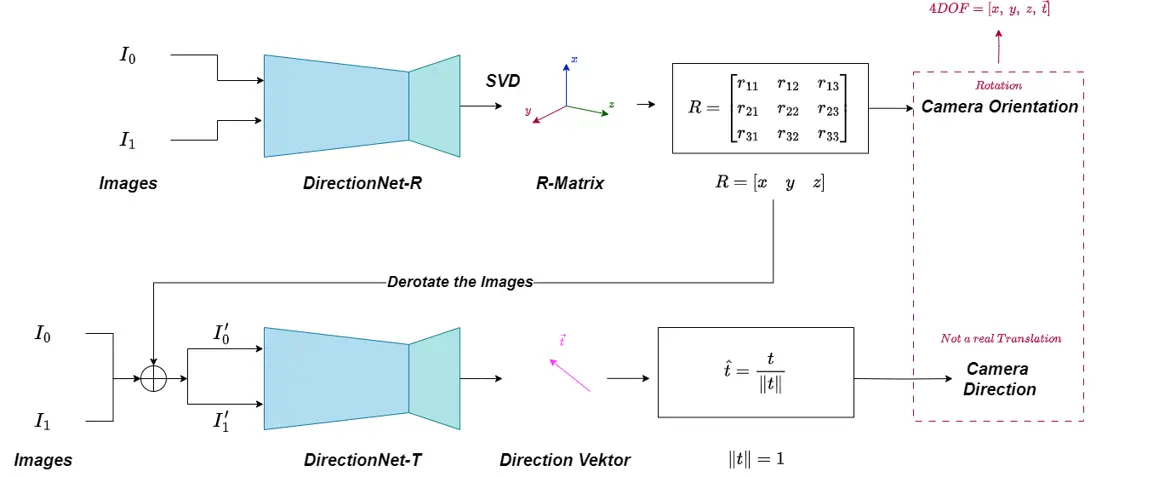
DirectionNet
DirectionNet-R & DirectionNet-T
Die Struktur „DirectionNet“ ist in zwei Teile unterteilt: DirectionNet-R und DirectionNet-T. Diese Struktur wird verwendet, um die Kamerarotation (Orientation) und die Kamerarichtung (Direction) zu bestimmen.
DirectionNet-R:
In diesem Teil werden zwei Eingabebilder (I₀ und I₁) in ein neuronales Netzwerk namens DirectionNet-R eingespeist. Anschließend wird durch die Methode der Singulärwertzerlegung (Singular Value Decomposition, SVD) eine Rotationsmatrix (R-Matrix) berechnet. Diese Matrix dient zur Bestimmung der Kamerarotation. Als Ergebnis werden die Werte mit vier Freiheitsgraden (4DOF) [x, y, z, ṫ] erhalten.
DirectionNet-T:
In diesem Abschnitt wird zunächst die zuvor berechnete R-Matrix verwendet, um die Rotation der Bilder zu korrigieren (Derotation). Danach werden die korrigierten Bilder (I₀' und I₁') in das neuronale Netzwerk DirectionNet-T eingespeist. Aus diesem Netzwerk wird ein normalisierter Richtungsvektor (Direction Vector) gewonnen, der die Kamerarichtung beschreibt. Dieser Vektor stellt zwar keine echte Translation dar, wird jedoch zur Bestimmung der Blickrichtung der Kamera verwendet.
Zusammenfassend kombiniert die DirectionNet-Struktur zwei unterschiedliche Netzwerkarchitekturen, um die Kamerarotation und -richtung präzise aus Bilddaten zu bestimmen.
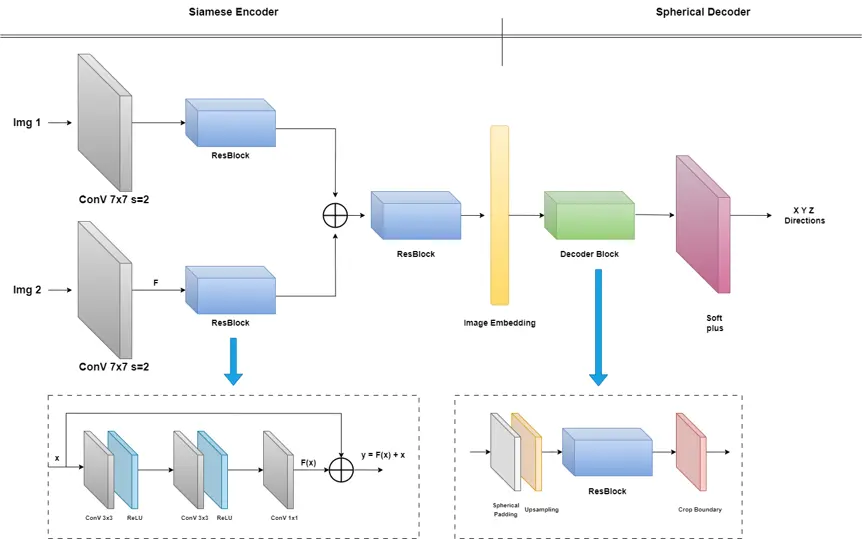
Ai Model
E2ENet Model System
Research Gaps
Leistungsverbesserung bei geringer Bildübereinstimmung:
Es besteht Bedarf an Methoden, die die Systemleistung auch bei geringer Übereinstimmung (Ähnlichkeit) zwischen Bildern verbessern können. Dieser Bereich weist auf die Notwendigkeit hin, neue Techniken zu entwickeln, die eine robustere Informationsgewinnung aus unterschiedlichen Bildern ermöglichen.
Reduktion des Einflusses dynamischer Objekte durch Transformer und GNN:
Transformer-Modelle können zeitlich variable Objekte aus den Bilddaten lernen und deren Einfluss auf die Ergebnisse reduzieren. Graph Neural Networks (GNN) wiederum wandeln Objekte in den Bildern in graphbasierte Strukturen um, wodurch die Verarbeitung durch Transformer-Blöcke erleichtert wird. Mit dieser Methode können die Beziehungen zwischen den Objekten klarer und effektiver modelliert werden.
Energieeffiziente Systeme für Echtzeitverarbeitung und kleine UAVs:
Systeme mit geringem Energieverbrauch und Echtzeitverarbeitung sollten so entwickelt werden, dass sie auch ohne komplexe Hardwarekomponenten (z. B. FPGAs) direkt in verschiedene Systeme integriert werden können. Dadurch wird eine effektive und effiziente Nutzung auf energiebegrenzten Plattformen wie kleinen unbemannten Luftfahrzeugen (UAVs) möglich.
Diese Forschungslücken definieren kritische Bereiche für zukünftige Studien und bieten bedeutende Chancen im Hinblick auf technologische Entwicklungen und praktische Anwendungen.
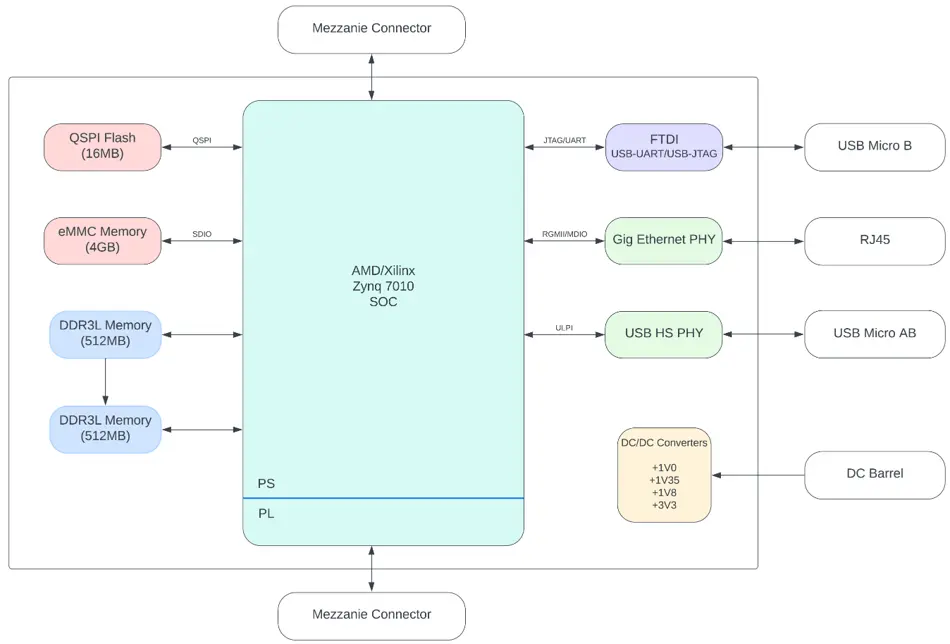
Spezielle Hardware Block Diagramm
Quellen
- K. Chen, N. Snavely and A. Makadia, "Wide-Baseline Relative Camera Pose Estimation with Directional Learning," 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021, pp. 3257-3267, doi: 10.1109/CVPR46437.2021.00327.
- Rockwell, Chris and Kulkarni, Nilesh and Jin, Linyi and Park, Jeong Joon and Johnson, Justin and Fouhey, David F. “FAR: Flexible, Accurate and Robust 6DoF Relative Camera Pose Estimation”, 2024, arxiv.org/abs/2403.03221
- Jianyuan Wang and Minghao Chen and Nikita Karaev and Andrea Vedaldi and Christian Rupprecht and David Novotny “VGGT: Visual Geometry Grounded Transformer”, 2025, arxiv.org/abs/2503.11651
THI Ansprechpartner


Wissenschaftlicher Mitarbeiter
Emre Tsaliskan
Tel.: +49 841 9348-6854
Raum: K307
E-Mail: Emre.Tsaliskan@thi.de
Emre Tsaliskan
Tel.: +49 841 9348-6854
Raum: K307
E-Mail: Emre.Tsaliskan@thi.de




